What is 301 redirect? Meaning and Definition.
A 301 redirect is a command performed by web servers (eg Apache, IIS, etc.) that redirects browsers requesting a certain URL to another URL. A common reason for setting up a 301 redirect is when a page’s URL has changed.
To ensure that internal and external links to the original URL continue to show visitors the original page, a 301 redirect is configured and the web server redirects traffic from the old URL to the new one.
According to John Mueller of Google, a 301 redirect will pass the PageRank to the new URL.
How LLMs Interpret 301 Redirects (And Why It’s Not Always What You Expect)
A 301 Redirect tells browsers and search engines that a page has permanently moved to a new URL.
But Large Language Models (LLMs) and AI crawlers do not always handle 301s the same way traditional search engines do.
LLM Crawlers Often Don’t Follow Redirect Chains Properly
Unlike Googlebot, which is engineered to follow long redirect chains, many AI crawlers:
- stop after the first redirect
- fail to follow chained redirects (301 → 301 → 200)
- time out on slow redirects
- ignore redirects that require JavaScript
- treat 301s differently depending on the user agent
This means an LLM may never reach the final destination page — even though the server returns a valid 301.
Firewalls Sometimes Block Redirected Requests
Security systems (Cloudflare, Akamai, Imperva, etc.) may:
- allow the first request
- block the redirected request
- serve a challenge page
- throttle the redirected URL
All of these can still return HTTP 301 → 200, but the LLM only sees:
- partial content
- a challenge page
- or nothing at all
This creates gaps in AI‑based indexing and grounding.
LLMs Don’t Transfer “Context” Through Redirects
Google transfers ranking signals through 301s.
LLMs do not transfer:
- topical context
- entity associations
- structured data
- brand information
- historical content
If the original page contained important information and the new page does not, the LLM will treat them as two separate entities, even if the redirect is technically correct.
Redirect Loops Confuse AI More Than Search Engines
Googlebot can detect and report redirect loops.
LLMs usually:
- stop crawling
- store incomplete data
- hallucinate missing information
- mis‑attribute content to the wrong URL
A redirect loop that Google handles gracefully may completely break AI understanding.
Why This Matters for AI Search, RAG, and Grounding
If your site relies on redirects for:
- content migrations
- URL restructuring
- canonical consolidation
- brand renaming
- product sunsetting
…then AI systems may not follow the same logic as Google.
This can lead to:
- outdated URLs being cited in AI answers
- missing or incomplete grounding
- hallucinated facts
- RAG systems retrieving the wrong page
- AI Overviews ignoring the new URL
Summary
A 301 Redirect is reliable for browsers and search engines — but not always for AI crawlers.
LLMs may stop early, fail to follow chains, or lose context entirely.
In the era of AI search, redirects must be tested not only for SEO but also for AI accessibility and grounding.
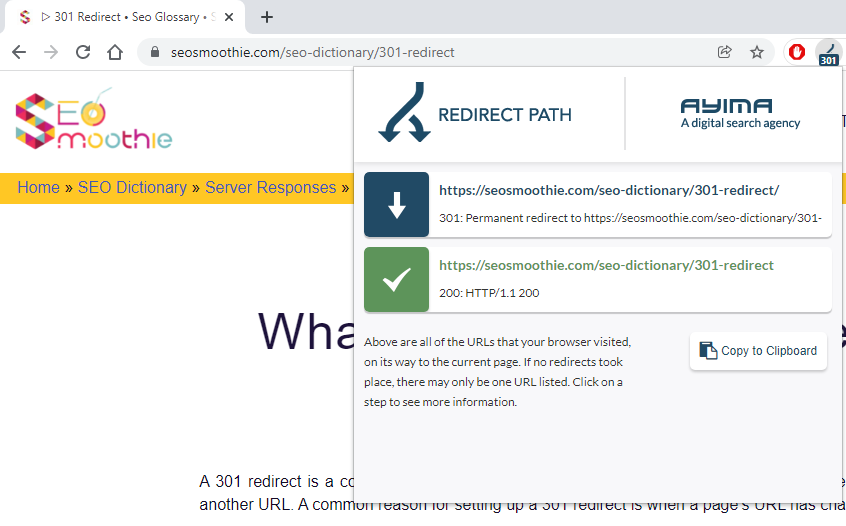
The free Google Chrome Redirect Path extension can be used to quickly check the response status code from a server for an individual URL.
You might also be interested in:
What is Noindex?
What is Redirect?
What is HTTP Header?
What is 404 Error?
What is Soft 404 Error?
301 redirect FAQ
Are 301 redirects bad?
Pages with 301 status codes do not technically exist and there is no point Google to crawl them. 301 Redirects are considered best practice in SEO. When executed properly, redirects will not harm your SEO rankings at all.
How many redirects is too many?
Don’t use more than 3 redirects in a redirect chain.
What is a 301 redirect?
A 301 redirect is a permanent redirect that passes all the ranking power to the redirected page.