Two standards bodies — WICG and the IETF — are now reviewing the same proposal:
a domain‑root, machine‑readable identity layer called the Semantic Anchor.
This post summarizes, in purely informational terms, what the proposal is, what problem it addresses, and what advantages it provides, based strictly on the published documents.
What Problem the Semantic Anchor Solves
Both the WICG proposal and the IETF Internet‑Draft describe the same structural issue:
The Identity Gap
AI crawlers, LLMs, and automated clients currently have no deterministic way to verify:
- who operates a domain
- what the canonical identity is
- whether metadata is authoritative
- how to establish trust in automated interactions
Existing mechanisms like llms.txt describe content, but not identity.
They are “unverifiable text surfaces.”
This leads to:
- attribution loss
- inconsistent entity resolution
- inability to verify authority or expertise
- reliance on probabilistic inference instead of deterministic identity
The Semantic Anchor is designed to close this gap.
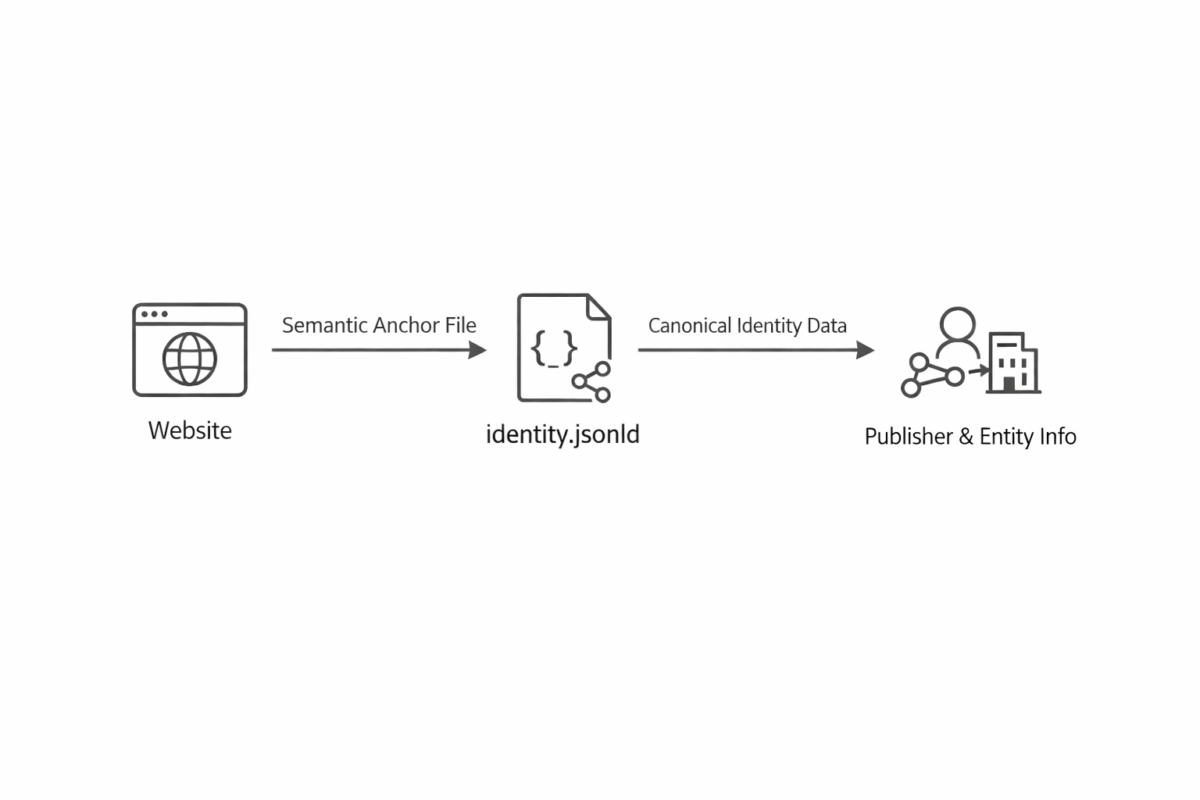
What the Proposal Introduces
Both documents define the same architectural pattern:
A domain‑root, machine‑readable JSON‑LD identity file, discoverable via predictable endpoints.
The identity node includes:
- @context: https://schema.org
- a persistent @id
- an Organization or Person identity
- canonical name
- optional legal provenance
- optional human expertise (credentials, occupation history)
Discovery mechanisms include:
- Identity header in llms.txt
- Identity: https://<domain>/identity.jsonld
- Well‑known URI
- https://<domain>/.well-known/identity.jsonld
- Optional HTTP response header
- Origin-Identity-Anchor: https://<domain>/identity.jsonld
These mechanisms ensure automated clients can reliably find the identity node.
What Advantages This Provides
1. Deterministic identity verification
Automated systems no longer need to infer identity from:
- page content
- scattered structured data
- external references
They can retrieve a single authoritative identity source.
2. Programmatic E‑E‑A‑T support
The identity node can include:
- legal registration
- credentialed human expertise
- organizational provenance
- service relationships
This enables machine‑readable authority modeling.
3. Stable foundation for AI discovery
The Semantic Anchor provides:
- a predictable discovery pattern
- a consistent identity reference
- a “Root of Trust” for AI‑to‑site interactions
- compatibility with existing retrieval systems
4. Proven real‑world functionality
As documented in both texts:
- Gemini autonomously discovered, fetched, and parsed the Semantic Anchor implementation at 1EuroSEO.com
- It incorporated the verified identity node into its reasoning
- No special instructions or modifications were required
This demonstrates backward compatibility with current LLM retrieval architectures.
Why It Appears in Both WICG and IETF
Although it is one proposal, it is being explored from two complementary perspectives:
- WICG → incubation of the web‑architecture pattern
- IETF → protocol‑level definition and transport considerations
Both documents share the same author and the same technical foundation.
Links to the Documents
- WICG Proposal #295
https://github.com/WICG/proposals/issues/295 - IETF Internet‑Draft
https://www.ietf.org/archive/id/draft-popov-webbotauth-semantic-anchor-00.html