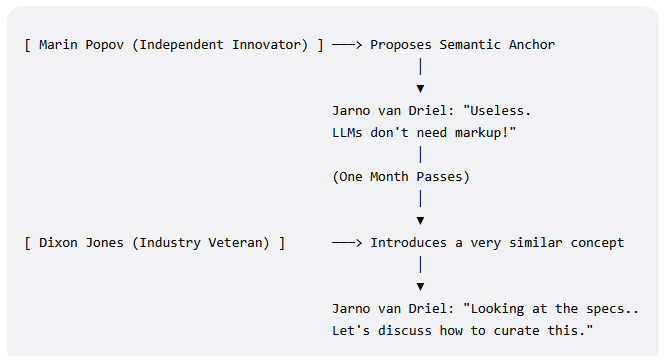
When independent developers propose fundamental shifts in web architecture, their innovations are often subjected to intense technical scrutiny. However, when the exact same architectural primitives are introduced by established industry figures, the nature of that scrutiny can shift dramatically.
Below is a direct, chronological look at how a single technical concept—using a domain-root file to map semantic entities for AI agents—was received by the exact same industry commentator within the span of just one month.
No commentary, sentiment analysis, or editorializing is needed. The documented text and timestamps speak entirely for themselves.
The paradox was initially noticed and exposed on https://www.linkedin.com/posts/marin-popov_ai-llms-seo-ugcPost-7468129568256761856-ld4M
Phase 1: The Conceptual Dismissal (April 2026)
The Context: Independent engineer Marin Popov introduces the Semantic Anchor, an architecture designed to bridge the AI “Identity Gap” by hosting a machine-readable discovery file at a website’s domain root to verify canonical identity for LLMs and crawlers.
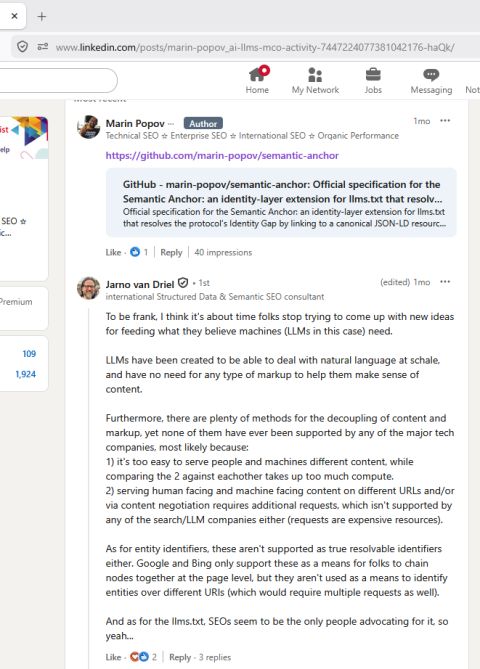
The Public Stance: Industry commentator Jarno van Driel reviews the proposal and publicly dismisses the fundamental utility of adding structured semantic layers for AI models:
“ To be frank, I think it’s about time folks stop trying to come up with new ideas for feeding what they believe machines (LLMs in this case) need.
LLMs have been created to be able to deal with natural language at schale, and have no need for any type of markup to help them make sense of content.
Furthermore, there are plenty of methods for the decoupling of content and markup, yet none of them have ever been supported by any of the major tech companies, most likely because:
1) it’s too easy to serve people and machines different content, while comparing the 2 against eachother takes up too much compute.
2) serving human facing and machine facing content on different URLs and/or via content negotiation requires additional requests, which isn’t supported by any of the search/LLM companies either (requests are expensive resources).
As for entity identifiers, these aren’t supported as true resolvable identifiers either. Google and Bing only support these as a means for folks to chain nodes together at the page level, but they aren’t used as a means to identify entities over different URIs (which would require multiple requests as well).
And as for the llms.txt, SEOs seem to be the only people advocating for it, so yeah… “
Link to the source: https://www.linkedin.com/posts/marin-popov_ai-llms-mco-activity-7447224077381042176-haQk
Phase 2: The Operational Collaboration (May 2026)
The Context: One month later, industry veteran Dixon Jones introduces a framework called EntityMap. The core architectural primitive is identical: placing an entity mapping file at the domain root for AI agents to discover, crawl, and parse.
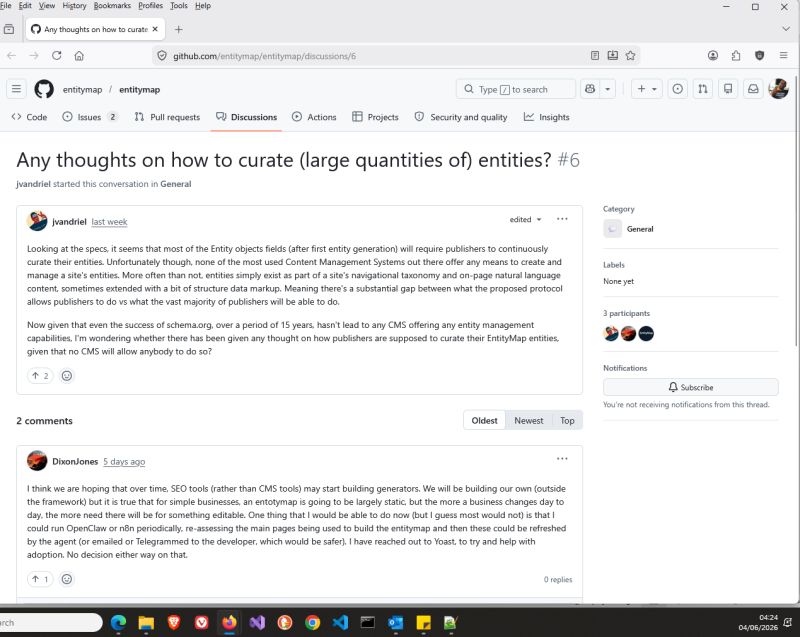
The Public Stance: Jarno van Driel enters the entitymap GitHub repository (Discussion #6). Instead of objecting that LLMs operate purely on natural language and do not need markup, he treats the domain-root specification as a valid operational framework and actively engages in solving its workflow hurdles:
“Looking at the specs, it seems that most of the Entity objects fields (after first entity generation) will require publishers to continuously curate their entities. Unfortunately though, none of the most used Content Management Systems out there offer any means to create and manage a site’s entities. More often than not, entities simply exist as part of a site’s navigational taxonomy and on-page natural language content, sometimes extended with a bit of structure data markup. Meaning there’s a substantial gap between what the proposed protocol allows publishers to do vs what the vast majority of publishers will be able to do.
Now given that even the success of schema.org, over a period of 15 years, hasn’t lead to any CMS offering any entity management capabilities, I’m wondering whether there has been given any thought on how publishers are supposed to curate their EntityMap entities, given that no CMS will allow anybody to do so?”
Link to the source: https://github.com/entitymap/entitymap/discussions/6
Conclusion: Let the Data (or the AI) Decide
By placing these two interactions side by side, the contradiction becomes clear. The underlying core technology—structuring data at the domain root for machine consumption—did not change between May and June. The only variable that changed was the name on the repository.
We choose to leave the final verdict entirely to the readers to decide for themselves.
However, if you find yourself lacking the technical sensibility to catch the subtle shift in behavior, simply feed these exact text strings into any modern Large Language Model. They are exceptionally well-equipped to catch any nuance and will explain the change of the sentiment right back to you.