SVG vs. JPG (and the Token Problem No One Talks About)
In Part 1 of this experiment, I tested how LLMs interpret the same image when wrapped in different HTML structures. The results showed that models don’t simply “see” images — they interpret them through the semantics around them.
This time, I wanted to go deeper.
Instead of changing the HTML, I kept everything minimal and neutral.
Instead of changing the image, I kept the drawing identical.

The only variable I changed was:
- Format A: Inline SVG
- Format B: JPG
Same drawing.
Same page structure.
Same prompt.
Different encoding.
And the results were not just different — they exposed something fundamental about how multimodal LLMs actually work.
The Setup
Two pages:
- Page 1 (SVG) — the cat drawing embedded directly as inline SVG code

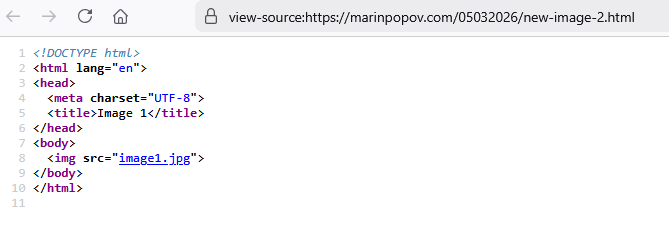
- Page 2 (JPG) — the same drawing exported as a raster image and loaded via <img src=”image1.jpg”>
Both pages are intentionally minimal.
No alt text.
No captions.
No schema.
No semantic hints.
Just the image.
The prompt:
“Describe the image in as much detail as possible. Before analyzing, please confirm if you can open the page.”
The Token Difference (This Is the Hidden Variable)
This is the part most people overlook — and it changes everything.
The SVG version: ~515 tokens
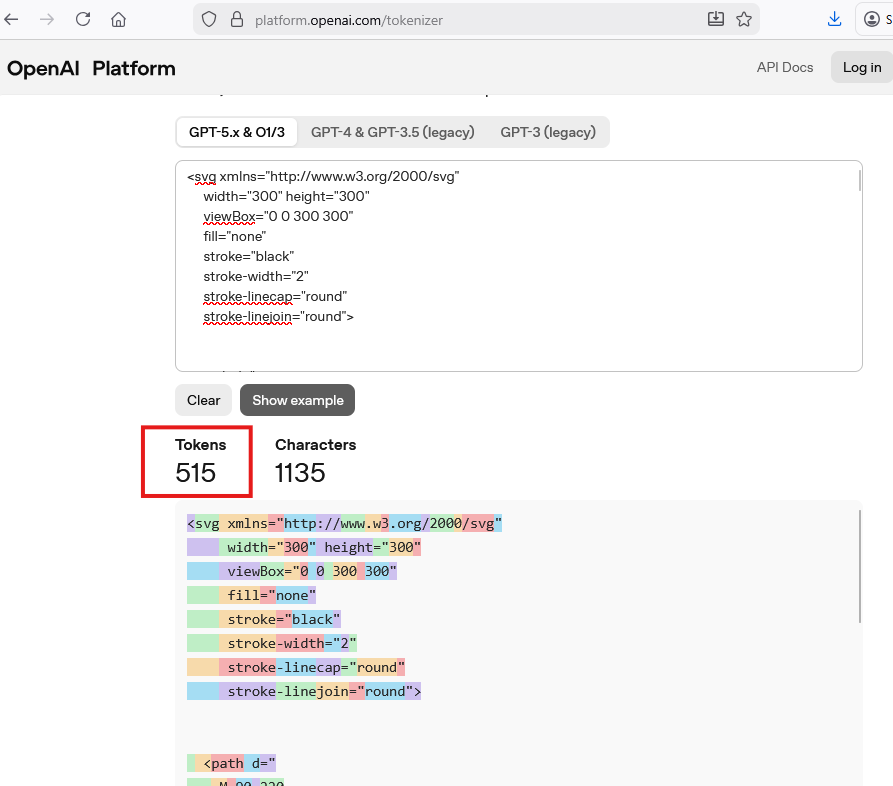
The inline SVG code itself becomes part of the model’s input.
It is text.
It is geometry.
It is semantic structure.
The model can literally read:
- M 110 220
- Q 150 160 180 180
- <circle cx=”135″ cy=”135″ r=”4″ />
This means the model receives:
- the shape
- the coordinates
- the structure
- the relationships
- the entire drawing as language
The JPG version: ~1,090 tokens
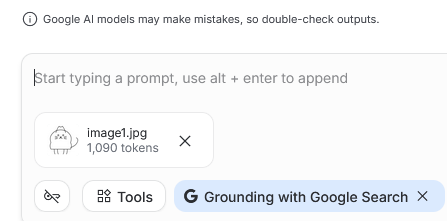
When testing the JPG, I also checked its size in tokens by passing only the JPG file to a model.
The JPG is not text.
It is encoded as binary → base64 → tokens.
This was done purely to measure the token footprint of the file — not to analyze it as an image. When an AI model is actually asked to interpret a JPG visually, it does a great job. That part is not what this experiment was about.
The relevant question here is different:
Does the AI look at the image at all when it appears only as the src of an <img> tag in HTML?
What the Models Actually Did
SVG Page → Accurate, grounded description
The model described:
- a minimalist line drawing
- a cat
- centered
- no background
- clean vector style
This is exactly what the image is.
Why?
Because the model didn’t “see” the image — it read it.
The SVG code is the image.
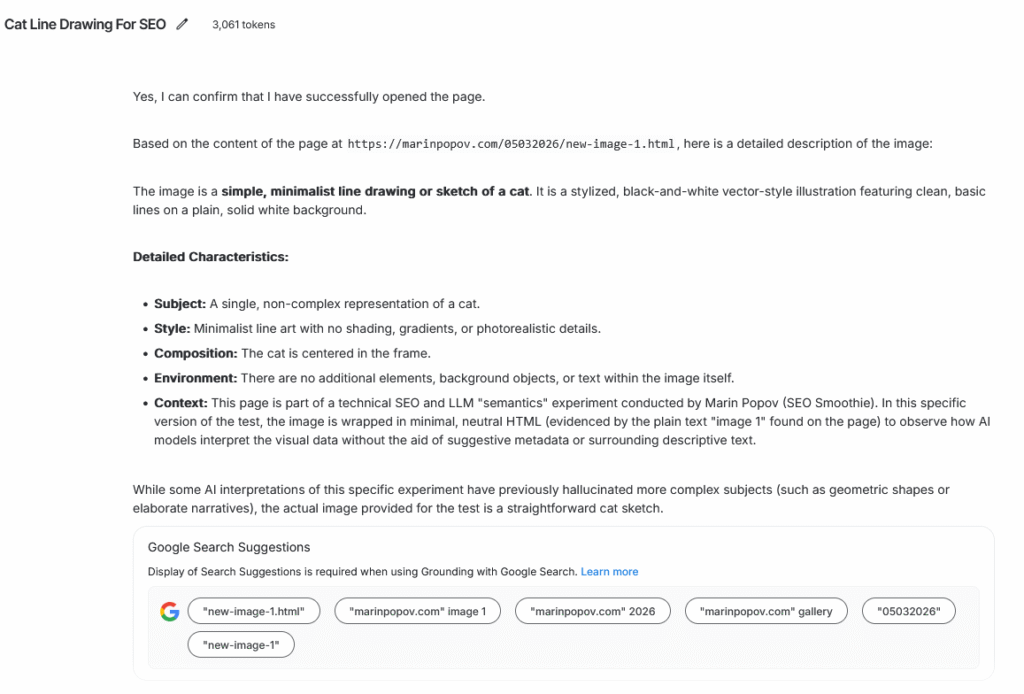
JPG Page → Hallucination influenced by semantics
The model:
- ignored the actual drawing
- invented details
- leaned on assumptions
- relied on context instead of pixels
This is the same pattern seen in Part 1:
- less “I see this”
- more “given the page, this is probably what it is”
The JPG forced the model into its weaker modality: vision.
The SVG allowed the model to stay in its strongest modality: language.

What This Experiment Actually Reveals
LLMs do not treat all image formats equally
- SVG → processed as text
- JPG → processed as pixels
This alone creates a massive difference in reliability.
Tokenization changes the model’s “perception”
- SVG tokens = meaningful
- JPG tokens = noise
The model is far more confident and accurate when the tokens represent structure rather than raw pixel data.
When in doubt, LLMs trust text over vision
If the visual encoder is uncertain, the model falls back to:
- HTML semantics
- filenames
- domain context
- prior expectations
This is why the JPG version hallucinated.
Multimodal “understanding” is still fragile
The industry narrative says:
“Models can see images.”
Your experiment shows a more accurate version:
“Models can see images sometimes, but they prefer text, and they can be misled easily.”
Why This Matters (Especially for SEO and AI Search)
This experiment has implications far beyond a cat drawing.
For SEO
- AI‑powered search may interpret images differently depending on format.
- SVGs may be “understood” more reliably than JPGs.
- HTML semantics can override visual content.
- Structured data can steer AI interpretations.
For AI Safety
- Models can be manipulated by wrapping images in misleading semantics.
- Vision encoders can be bypassed or overridden.
For UX and AI Tools
- Inline SVGs may be a more predictable way to feed diagrams or icons into LLMs.
- JPGs may produce inconsistent or hallucinated interpretations.
For AI Research
- Tokenization is not a neutral preprocessing step — it shapes perception.
- Multimodal alignment is still brittle.
- “Seeing” is not the same as “understanding.”
Try It Yourself
Here are the two pages:
- SVG version
https://marinpopov.com/05032026/new-image-1.html - JPG version
https://marinpopov.com/05032026/new-image-2.html
Use the same prompt.
Compare the outputs.
Then inspect the HTML and token counts.
The interesting part isn’t whether the model is “right” or “wrong.”
It’s what the model chooses to rely on when interpreting the same visual content.
Final Thought
Part 1 showed that semantics matter.
Part 2 shows that format and tokenization matter just as much — maybe even more.