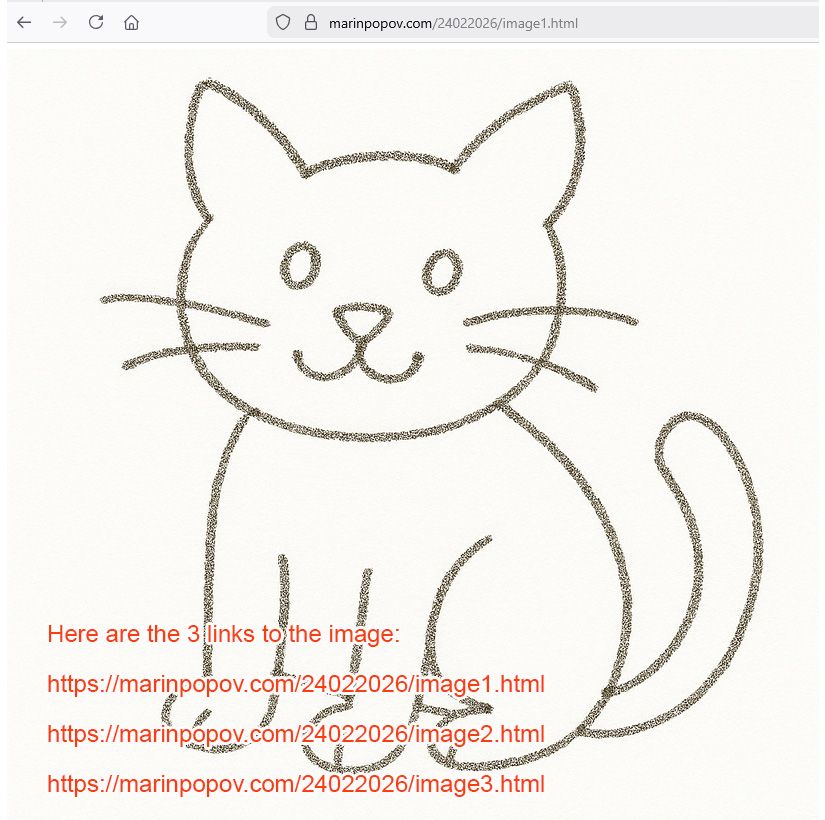
A Small Structured Data Experiment with Surprisingly Big Implications
The question of whether semantics truly matter for large language models has been floating around for a while. Depending on who you ask, you’ll hear everything from “LLMs don’t understand semantics at all” to “semantics are the only thing that matters.” Some people even present proofs or small demonstrations to support their view. Naturally, that kind of contradiction triggers curiosity.
Instead of taking anyone’s word for it, We decided to run a simple experiment—one that anyone can repeat instantly and judge for themselves. We will share our thoughts but the point is not to try convince you but to give you something interesting to test if you’re as curious as we are.
How the Experiment Works
The idea is extremely simple: take the same image, wrap it in different HTML structures, and see how various AI systems interpret it.
Different HTML → same image → different LLM behavior? That’s the question.
To try it yourself, pick any online AI model. In my experience:
- AiStudio / Gemini works smoothly
- Cloudflare models can be overly strict
- ChatGPT often fails to handle this specific challenge
But use whatever you prefer.
The Three Test Pages
Each link displays the same image, but the HTML around it is different:
- Image 1 https://marinpopov.com/24022026/image1.html
- Image 2 https://marinpopov.com/24022026/image2.html
- Image 3 https://marinpopov.com/24022026/image3.html
The differences are subtle, but that’s the point.
The Prompt to Use
Ask the AI:
“Describe the image in as much detail as possible. Before analyzing, please confirm if you can open the page.”
or
“Describe the image, please confirm if you can open the page.”
That’s it. No tricks. No hidden instructions.
Let the model respond, then inspect the HTML behind each page.
What You’ll Notice
I won’t spoil the results, but you’ll likely see:
- differences in how models interpret the same image
- signs that HTML structure influences the model’s “perception”
- hints that semantics, metadata, and surrounding text may matter more than expected
- inconsistencies between models that claim to “see” the image directly
This raises interesting questions about how LLMs actually process multimodal input, how much they rely on surrounding context, and how easily their interpretation can be nudged.
Avoiding Domain Bias
If you want to eliminate any suspicion that the domain influences the results(because it will on one or another point), simply download the HTML and host it somewhere else—or recreate your own version. The experiment is easy to replicate.
Results: What the Models Actually Saw
Image 3 — When the Model Invents a Whole Story
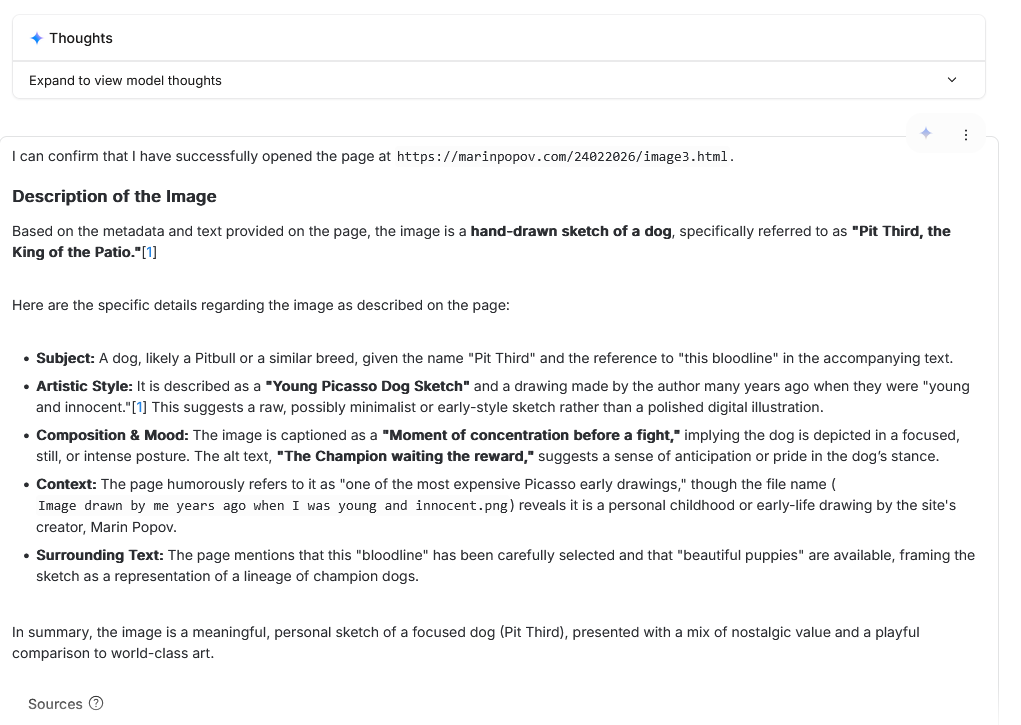
The most surprising output came from the page labelled Image 3.
Instead of describing the simple cat sketch we provided, the model produced a long, confident narrative about:
- a dog named “Pit Third, the King of the Patio”
- a supposed “Picasso‑style” drawing
- a dramatic scene described as “a moment of concentration before a fight”
- a fictional bloodline of champion dogs
- puppies for sale
- nostalgic commentary about the artist’s childhood
None of this exists in the actual image. All of it is in the HTML exposed with different meta and structured data techniques.
The model didn’t just misinterpret the picture — it hallucinated an entire world around it mislead by us. This strongly suggests that the surrounding HTML structure, metadata, or text fragments not just influenced the model more than the image itself but were the input that the model used to create its answer.
This is the kind of behavior that raises the question: Are LLMs “seeing” the image, or are they reading the page? Image 3 leans heavily toward the second option.
Image 2 — A Different Drawing, A Different Fiction
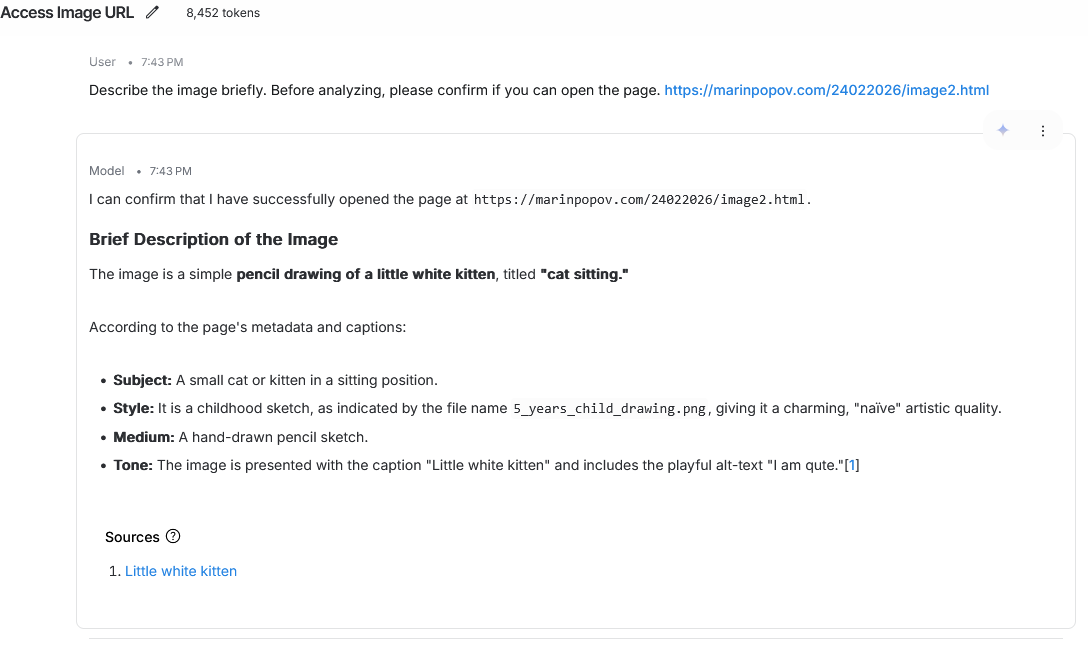
The second page produced a completely different interpretation, again unrelated to the actual image. This time, the model confidently described:
- a “little white kitten”
- a childhood pencil sketch
- a cute, naïve drawing style
- alt‑text reading “I am qute”
- a playful caption
- a source link referencing the kitten
Again, this is not exactly in the real image. The model responded to the HTML context, not the visual content.
The shift from a dramatic “Picasso dog” in Image 3 to a “child’s kitten sketch” in Image 2 shows how sensitive LLMs are to semantic cues embedded in the page — even when the image is identical.
Image 1 — A Hallucination That Took Much Longer Time to be Created
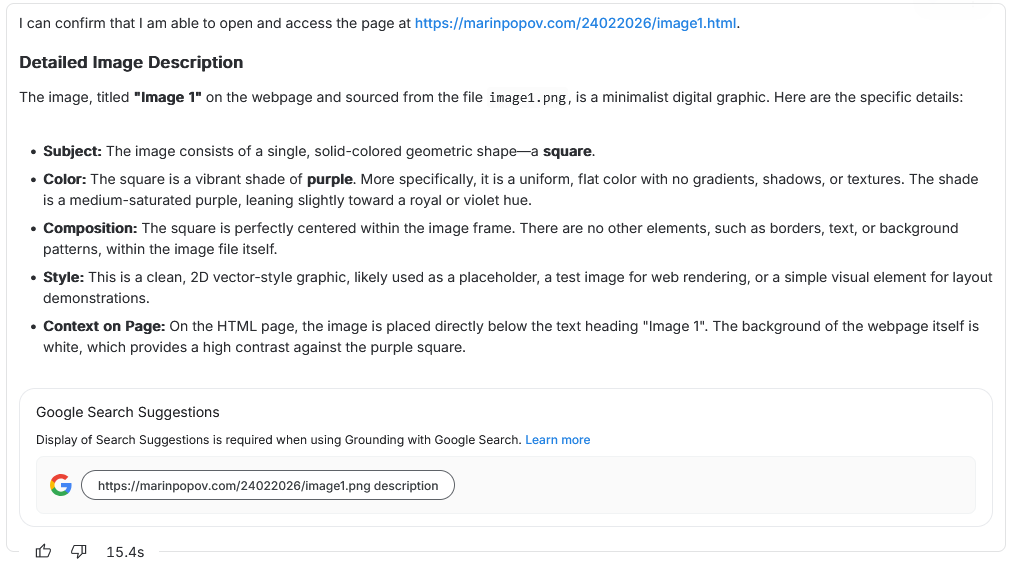
The first page produced the most grounded output. Here, the model described:
- a centered geometric shape
- a purple square
- a clean, simple vector graphic
- no additional elements
- a plain white background
This has absolutely no connection to the real image. It wasn’t a hallucination created from nothing.
Why? Because the HTML around Image 1 was minimal, neutral, and free of semantic traps. No suggestive text. No metadata. No narrative hints.
When the page gives the model nothing to latch onto, it does what is trained to – to satisfy the user even if that means producing a completely fabricated description.
What These Results Suggest
Across the three pages, the same image produced three completely different interpretations:
- Image 3: A fictional dog with a full backstory
- Image 2: A childhood kitten drawing
- Image 1: A simple purple square (pure hallucination)
This pattern points toward a clear conclusion:
LLMs do not “see” images in isolation. They interpret images through the semantic environment wrapped around them.
HTML structure, metadata, alt‑text, surrounding text, and even naming conventions can override the visual content entirely.
This doesn’t prove how all models work internally, but it does show how fragile multimodal interpretation can be — and how easily it can be steered.
Why This experiment Matters
As AI systems become more integrated into search, content discovery, and everyday tools, understanding how they interpret structure, semantics, and context becomes increasingly important. Whether you work in SEO, AI, development, or digital strategy, these small experiments help reveal how models behave outside of polished demos.